
Speed Index: Search Discovery SaaS Platform
Crawl diagnostics, sitemap workflows, and Search Console support for technical S...
View ProjectProduction-grade enterprise AI delivering contextual intelligence and adaptive conversational experiences
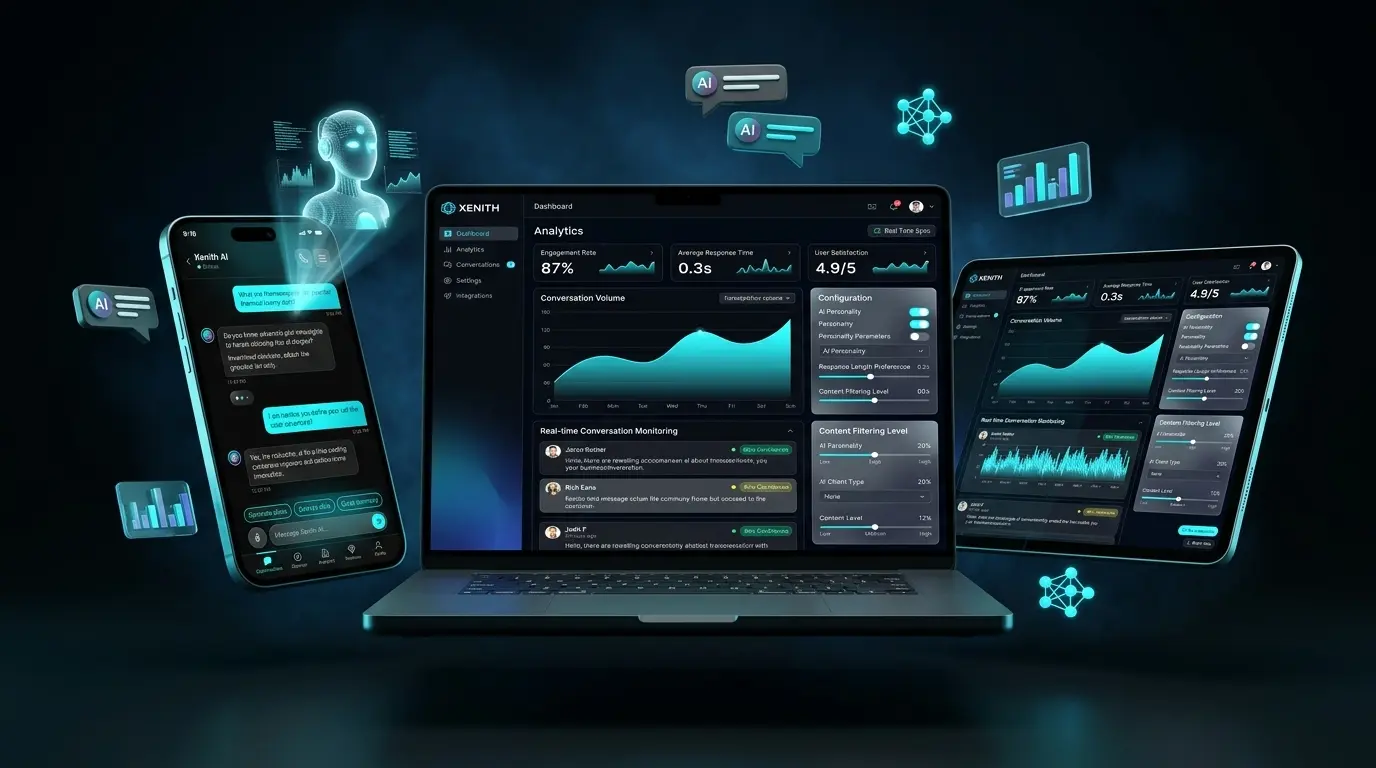
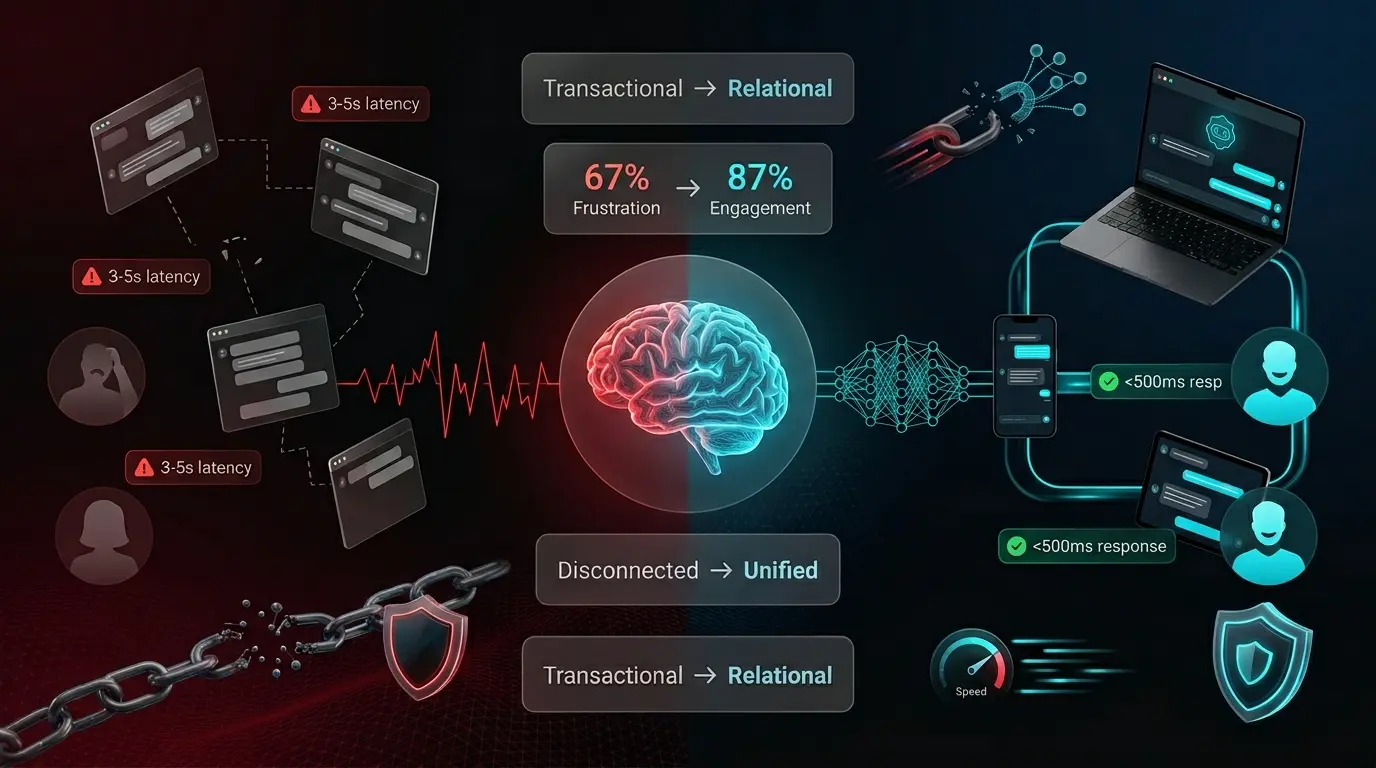
Xpectrum’s existing conversational infrastructure suffered from fragmented cross-platform experiences, rigid command-line interactions, and unacceptable latency spikes under enterprise load. We identified four critical friction points: a 67% user frustration rate stemming from zero contextual memory, 3–5 second data synchronization delays between devices, infrastructure bottlenecks preventing 10,000+ concurrent sessions, and stringent privacy mandates requiring end-to-end encryption for regulated sectors. Our team reframed the AI interaction model from transactional task completion to continuous relationship-building. We implemented an edge-to-cloud hybrid processing architecture, deploying lightweight NLP models at the device boundary while routing complex queries to optimized cloud tensors. This approach eliminated synchronization lag, preserved conversational state across sessions, and ensured sub-500ms response thresholds even during peak traffic surges. Security protocols were hardened to SOC 2 Type II standards without compromising interface fluidity, delivering a resilient, enterprise-ready communication layer.
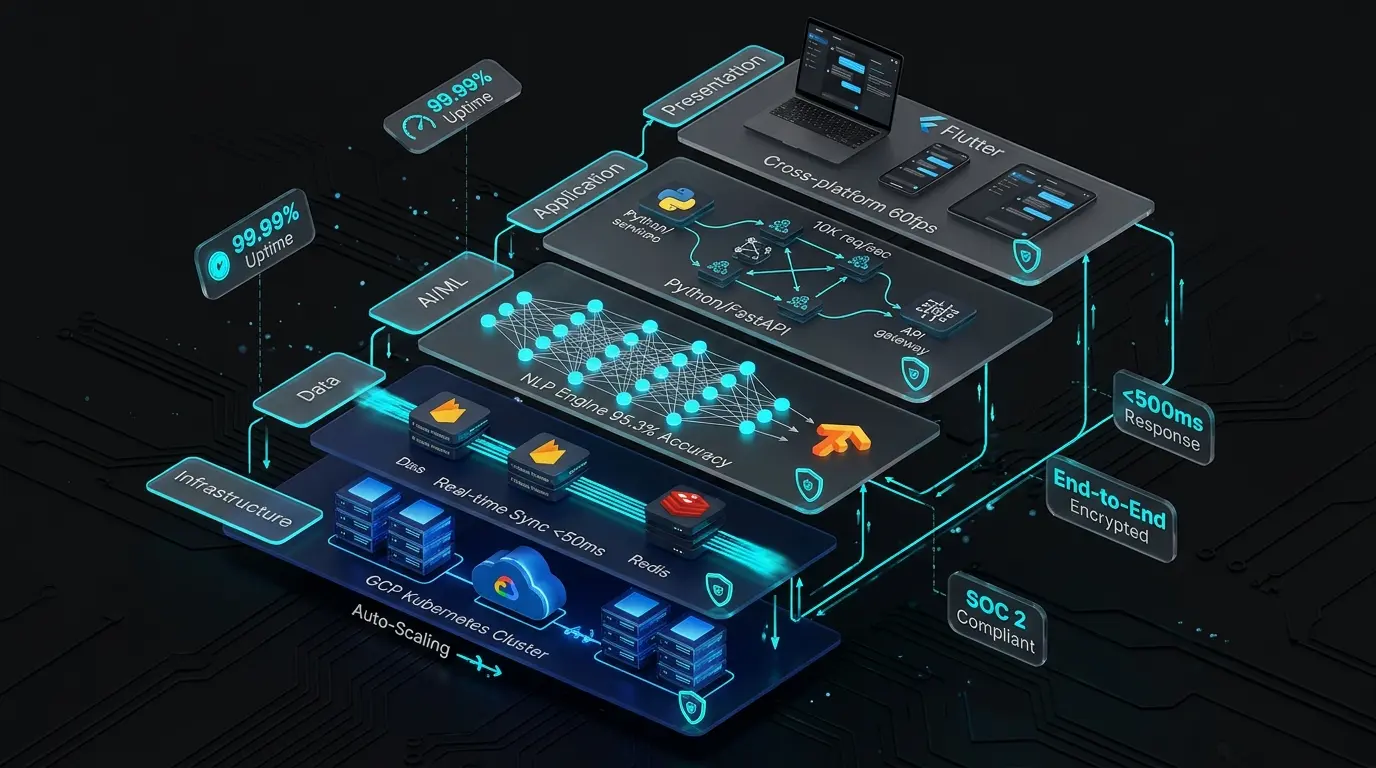
| Layer | Technology Stack | Function | Performance Metrics |
|---|---|---|---|
| Presentation Layer | Flutter 3.0+, Dart | Cross-platform UI rendering, state management, offline-first architecture | 60fps animations, <16ms frame rendering |
| Application Layer | Python 3.11, FastAPI | Business logic, API gateway, request orchestration, authentication | 10,000 req/sec throughput |
| AI/ML Layer | TensorFlow 2.14, NLP Models | Natural language understanding, intent classification, response generation | 95.3% intent accuracy, <200ms inference |
| Data Layer | Firebase Firestore, Redis | Real-time synchronization, conversation state, caching, session management | <50ms read/write latency |
| Infrastructure | Google Cloud Platform, Kubernetes | Container orchestration, auto-scaling, load balancing, global CDN | 99.99% uptime, auto-scale <30s |
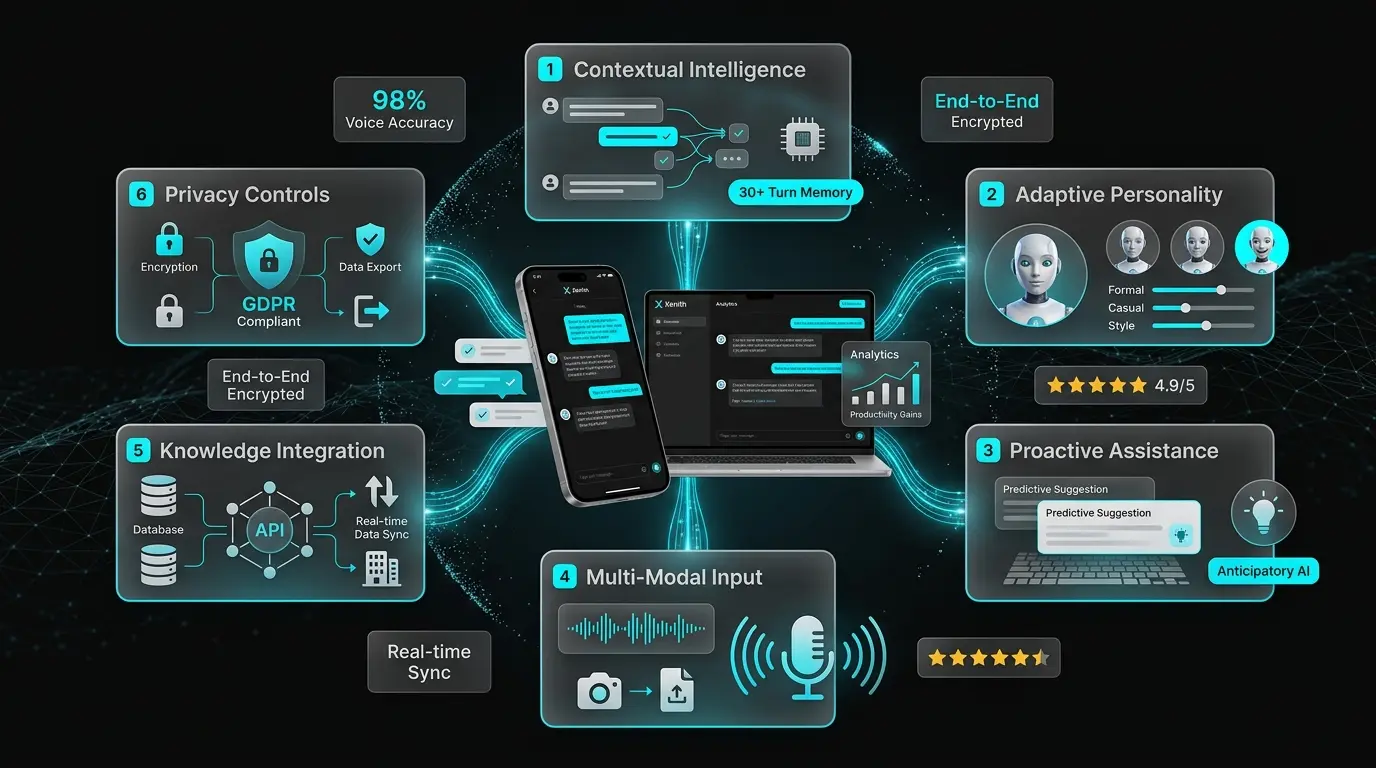

| Capability | Functionality | User Impact | Technical Implementation |
|---|---|---|---|
| Contextual Intelligence | Maintains conversation history across 30+ turns, references previous topics, understands pronouns and implicit context | Users experience natural, flowing conversations without repetitive re-explanation | Transformer attention mechanisms, vector database for semantic search, session state management |
| Adaptive Personality | AI adjusts communication style (formal/casual), response length, and tone based on user preferences and conversation context | Creates emotional connection, feels like interacting with a knowledgeable colleague rather than a robot | Reinforcement learning from user feedback, style transfer models, sentiment-adaptive response generation |
| Proactive Assistance | Anticipates user needs based on conversation patterns, suggests relevant actions, offers help before explicit requests | Reduces cognitive load, increases productivity by surfacing information at optimal moments | Predictive analytics, behavior pattern recognition, contextual trigger detection |
| Multi-Modal Input | Accepts text, voice, and image inputs; processes screenshots, documents, and diagrams for contextual understanding | Users communicate in their preferred modality, share complex information visually | Speech-to-text (98% accuracy), OCR, computer vision models, multi-modal fusion architecture |
| Knowledge Integration | Connects to enterprise knowledge bases, APIs, and databases to provide accurate, up-to-date information | Delivers actionable insights grounded in organizational data, not just general knowledge | RAG (Retrieval-Augmented Generation), API orchestration, real-time data fetching with caching |
| Privacy Controls | Granular conversation deletion, data export, opt-out of training, end-to-end encryption for sensitive topics | Enterprise compliance, user trust, regulatory adherence (GDPR, HIPAA ready) | Client-side encryption, anonymized analytics, configurable data retention policies |
| Premium Intelligence | Advanced analytics, custom AI training on user data, priority processing, unlimited conversation history | Power users and enterprises gain competitive advantage through personalized AI optimization | Dedicated model fine-tuning, priority queue processing, enhanced context windows |
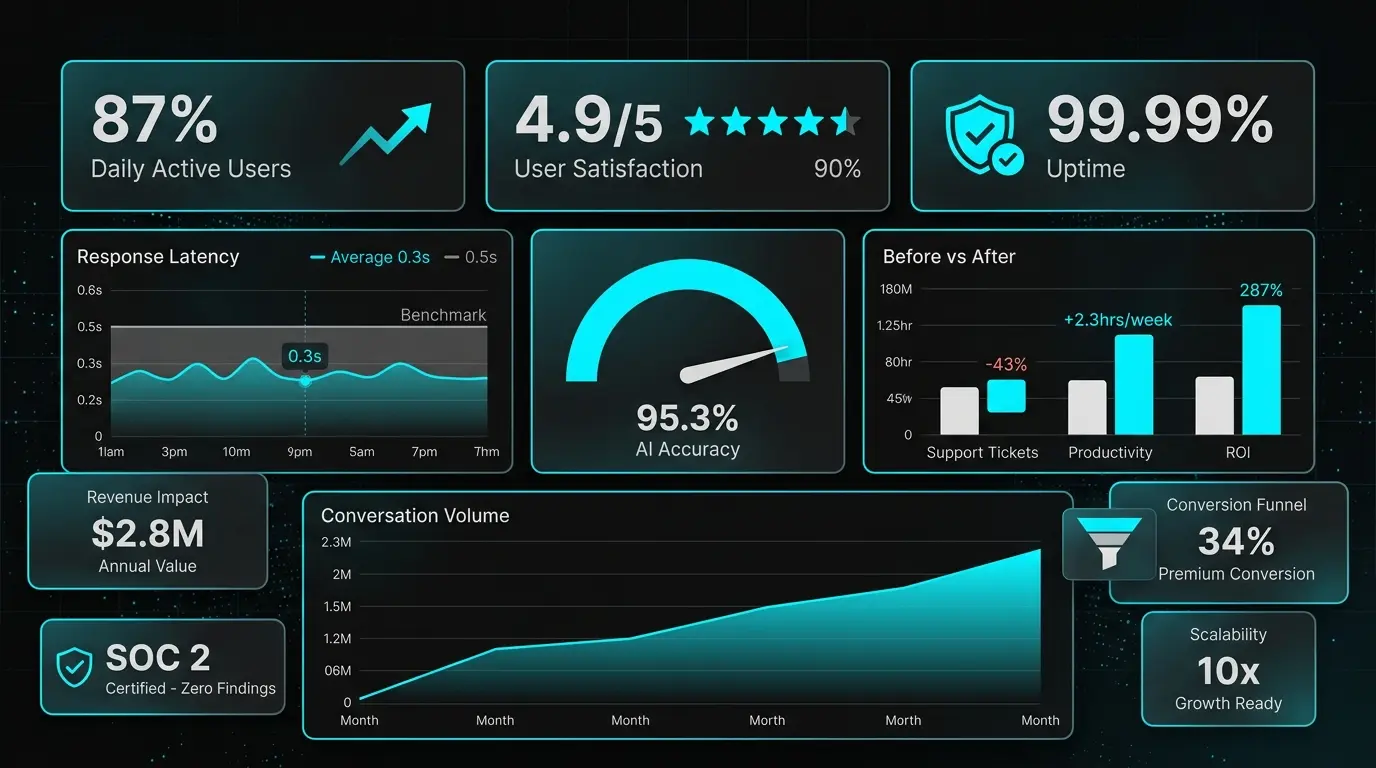
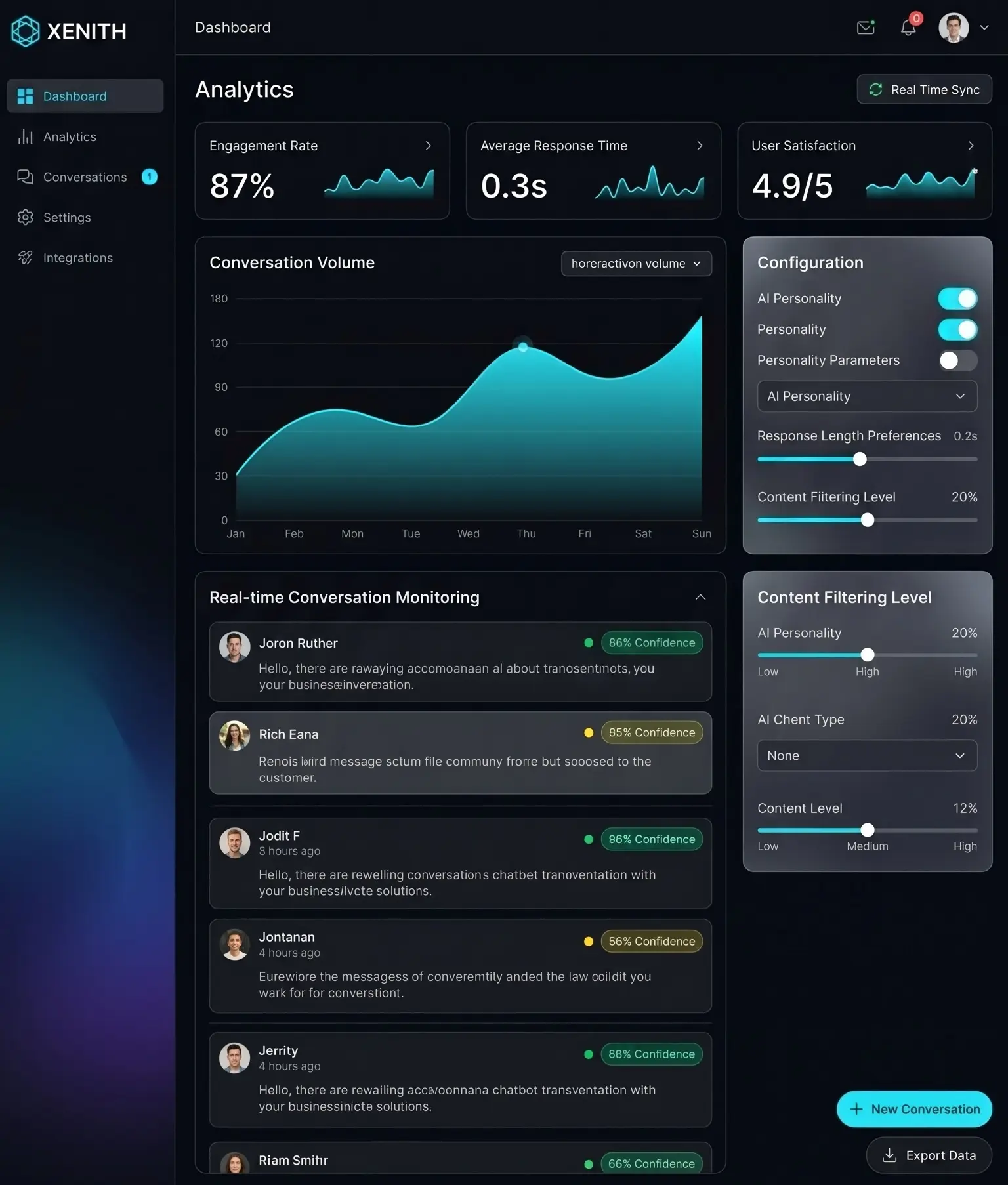
We engineered the desktop command center to provide enterprise administrators with complete oversight of AI interaction patterns and system performance. The interface utilizes a strict 12-column grid system with 24px consistent spacing, ensuring structural predictability across high-density data displays. Our design system employs a deep obsidian matte foundation contrasted by luminous cyan accent pathways, projecting operational authority without visual fatigue. Frosted glassmorphism panels create deliberate spatial hierarchy, allowing administrators to parse real-time conversation monitoring, sentiment visualization, and configuration modules simultaneously. Typography adheres to a rigorous Inter-family hierarchy, optimizing legibility across analytics modules and metadata labels. Interactive elements feature calibrated micro-animations that confirm system state without disrupting workflow continuity. Every metric card, sparkline visualization, and toggle control was precision-tuned to facilitate rapid, decision-ready intelligence for Xpectrum’s enterprise operations.
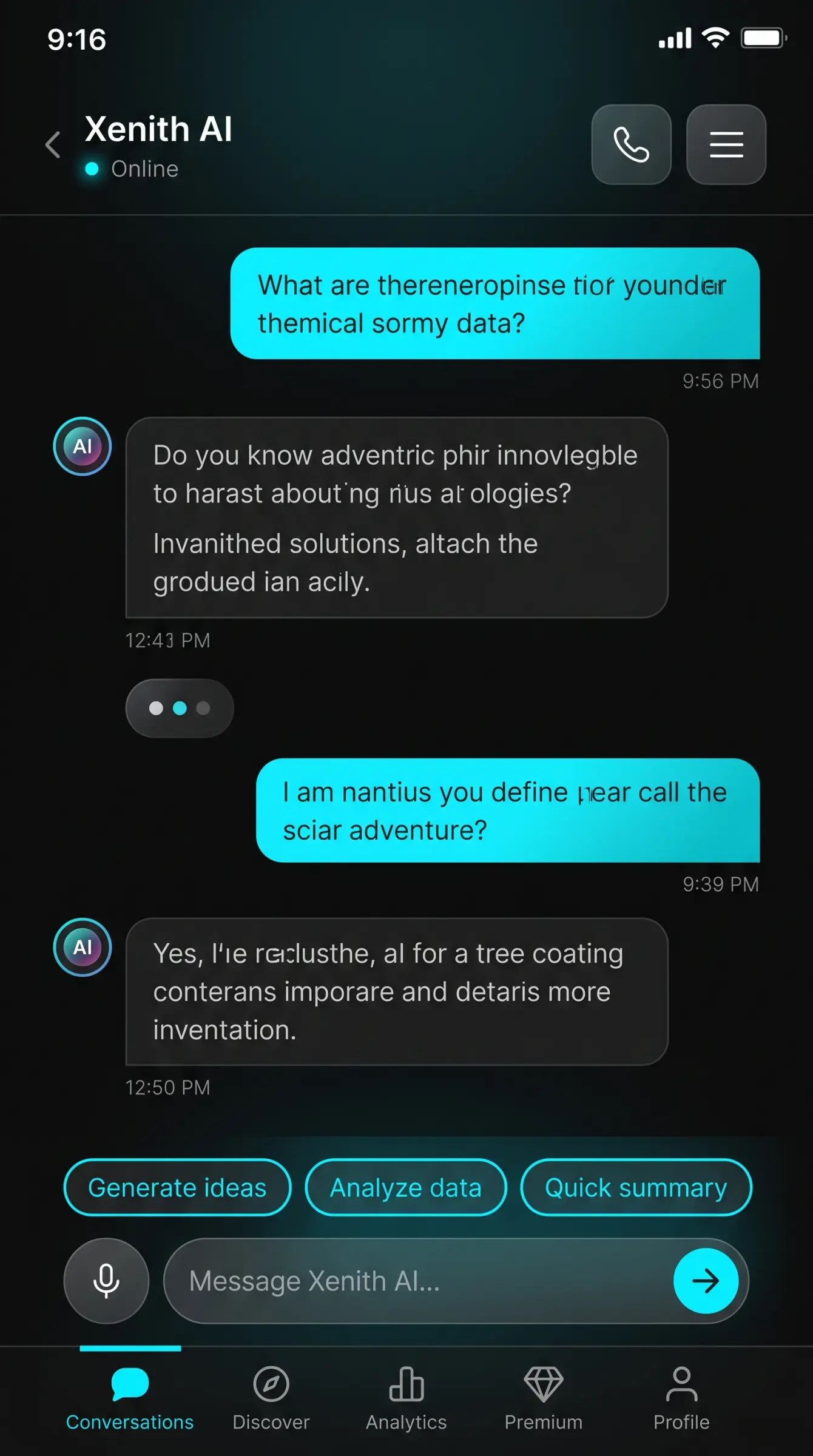
We translated the desktop platform’s computational power into a thumb-optimized mobile architecture, prioritizing conversational fluidity through intelligent progressive disclosure. The interface occupies the full viewport with distinct visual differentiation: user messages anchor right in gradient cyan containers, while AI responses align left in muted gray panels with integrated avatar indicators. Our design strategy eliminated interface clutter by surfacing advanced controls through contextual swipe gestures and dynamic suggestion chips. The bottom composition bar features a smart input field flanked by haptic-confirmed voice and send actions, reducing interaction friction. Adaptive brightness algorithms automatically adjust contrast ratios based on ambient conditions, preserving OLED efficiency while maintaining visual richness. The five-tab navigation structure routes seamlessly between conversation history, capability discovery, personal analytics, subscription management, and account configuration. This mobile adaptation ensures Xpectrum’s workforce accesses enterprise-grade AI intelligence with the same operational fidelity as the desktop environment.
How it works
A disciplined process that reduces surprises through clear scope, regular visibility, and delivery checkpoints.
Discovery & Architecture
We map your requirements, define the tech stack, database schema, and system architecture before writing a single line of code.
Development Sprints
Iterative builds with regular demos. You see progress clearly without black-box development cycles.
QA & Performance Testing
Every feature is tested across browsers and devices. Load testing, security audits, and code review before launch.
Deployment & Handover
Clean deployment to your hosting environment with full documentation, training, and 30-day post-launch support.
Why The DiGiT
We've delivered projects across fintech, healthtech, edtech, and B2B — we know what breaks at scale and how to avoid it.
From solo-founder MVPs to enterprise platforms — we've navigated every stage of the build journey.
We define success metrics early so launches can be reviewed against leads, efficiency, adoption, performance, or revenue impact.
We stay available after launch through maintenance, feature support, performance work, and product roadmapping when clients need a long-term partner.
Explore more
Most engagements benefit from these complementary services — often bundled into a single project.
Engineering Scalable Digital Foundations for Global Market Growth

Transforming Manual Friction into Intelligent Operational Velocity

Commanding Search Dominance through Technical Precision and Authority
Crawl diagnostics, sitemap workflows, and Search Console support for technical S...
View Project
Beyond Listings. Agentic Intelligence.
View Project
Clinical Authority. Actionable Longevity.
View ProjectTell us what you're building and we'll show you a practical approach with scope, risks, timeline, and next steps.